【导语】
ASV-Subtools是厦门大学智能语音实验室(XMUSPEECH)于2020年6月推出的一套高效、易于扩展的声纹识别开源工具,该工具是基于Kaldi与Pytorch开发的,充分结合了Kaldi 在语音信号和后端处理的高效性以及PyTorch 开发和训练神经网络的便捷灵活性。
ASV-Subtools 自开源以来,就以卓越的性能和灵活便捷的框架受到国内外重点科研院所和研发人员的青睐,先后在东方语种、CNSRC等竞赛中提供基线系统,并且在VoxCeleb数据集上取得了SOTA的结果。CNSRC脚本和此次更新得到厦门天聪智能软件有限公司(TalentedSoft)的协助。
【更新介绍】
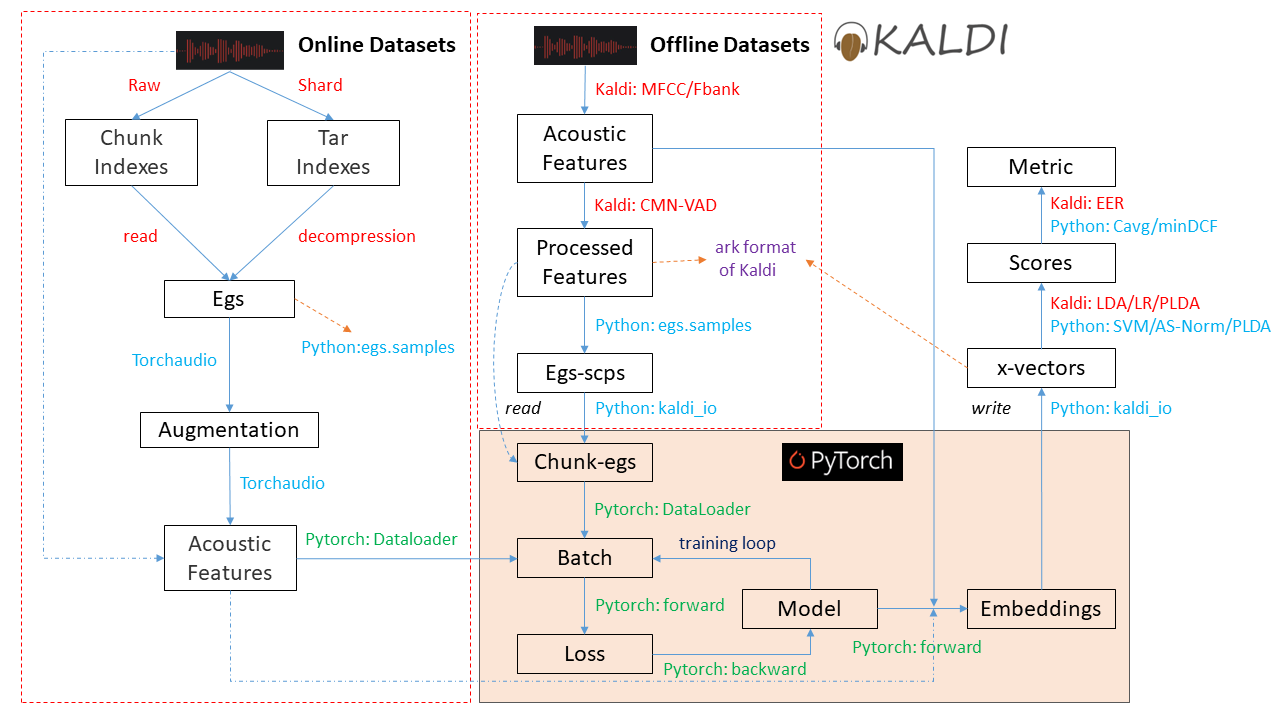
ASV-Subtools原有的训练模式为离线模式,即采用的是原生的Pytorch Dataset,训练样例主要存储在csv文件中,每个样例为一行,其中信息主要包含数据路径、对应标签等,这里的数据为Kaldi格式的特征存储路径;在训练流程中,可以根据存储位置进行数据读取并与其对应的标签组合成训练样例。然而,随着数据量的增加,原有离线训练模式已不能满足高效研发的需求:频繁的IO读取会导致显存占用高但利用率低的问题。
图1 ASV-Subtools中的数据处理流程
因此为了满足大规模数据训练的需求,ASV-Subtools参考借鉴了WeNet、Speechbrain等优秀开源框架的架构,新增了在线训练模式,并从以下三个方面进行更新:
(1)大规模数据读取下的IO改进。
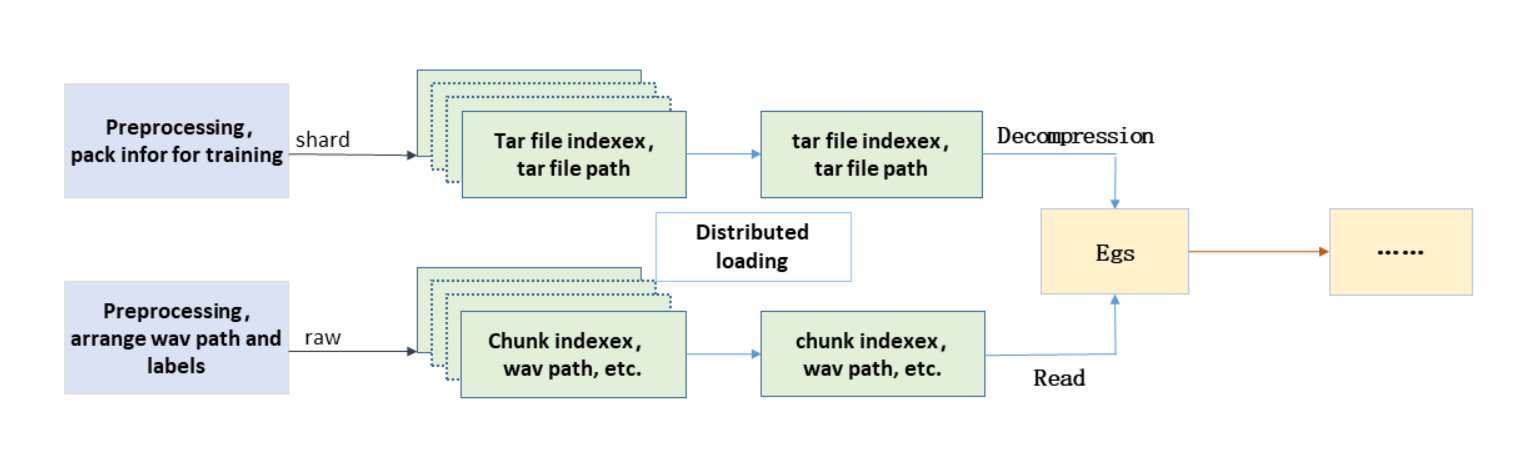
图2 ASV-Subtools在线数据处理方案
在线数据处理方案分为两种模式:普通模式和分片模式。普通模式与离线模式类似,普通模式数据预处理时生成训练所需的样例索引,之后进行在线读取,适用于小数据集。分片模式则会将普通模式的样例进一步存储并打包至压缩包中,压缩后索引数量为压缩包数量,解决索引文件过大的问题,避免重复读取同条长语音,缓解读入时的内存压力。同时,压缩包内数据可顺序读取,加快读取速度。
(2)混合精度训练。
在主流深度学习框架中,浮点数默认为FP32(32位4字节存储格式),也称作单精度浮点数。低精度浮点数是指存储量占用更少的数据类型,如FP16为16位2字节存储格式,因此它所能表示的精度和范围也会更低。随着支持低精度计算的张量核心的普及,低精度计算正在一步步走向成熟。混合精度训练的目标是尽量在不影响整体模型精度的情况下,将参数部分变为低精度以实现加速训练、节省显存的目的。
(3) 在线数据扩增。
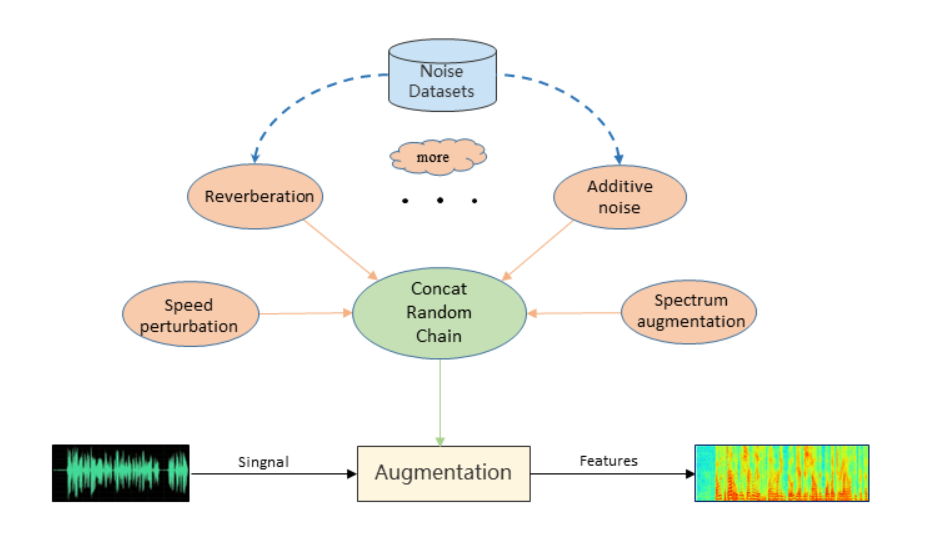
在Kaldi框架下,一般采用离线扩增,即在模型训练前准备好扩增好的特征文件并存入磁盘中,后续进行读取。这样方式需要为每次不同的扩增策略重新生成特征,而在大规模数据场景下特征会占用很大的空间,对存储空间要求较高。而采用在线数据扩充策略,一方面可以起到节省空间的目的,另一方面在特征配置时更加灵活,提高数据扩充的灵活性,增加样本的多样性。
图3 ASV-Subtools在线数据扩充示意图
【最新结果】
新增的在线训练模式刷新了此前ASV-Subtools在VoxCeleb数据集上的最优结果,再次取得了SOTA的水平,相关复现脚本均已更新至Github,读者可以在GitHub上获得更多测试结果和详细的实验配置,感兴趣的读者赶紧上手试试吧!
VoxCeleb2上ResNet34模型的测试结果:
VoxCeleb2上ECAPA模型的测试结果:
【其他更新】
除上述更新以外,此次ASV-Subtools的更新还包括以下内容:
1、XMUSPEECH针对标签噪声(Lable Noise)问题的最新研究成果的源码已更新至ASV-Subtools,该研究成果“When Speaker Recognition Meets Noisy Labels: Optimizations for Front-ends and Back-ends ”已被语音领域国际顶级期刊《IEEE/ACM Transactions on Audio, Speech, and Language Processing》(IEEE/ACM-TASLP)接收。XMUSPEECH针对语速对抗问题的最新研究成果的源码已更新至ASV-Subtools,该研究成果“Deep Representation Decomposition for Rate-Invariant Speaker Verification”已被国际顶级说话人和语种识别研讨会 (Odyssey 2022)接收。
论文原文:https://www.isca-speech.org/archive/odyssey_2022/tong22_odyssey.html
2、新增部分模型,例如RepVGG、RepSPK等。
3、支持JIT模型转化,并且模型落地的RUNTIME模块在下一步开源计划中,敬请期待~
【GitHub】
https://github.com/Snowdar/asv-subtools
欢迎各位读者关注、点星、提意见~
【参考文献】
Fuchuan Tong, Miao Zhao, Jianfeng Zhou, Hao Lu, Zheng Li, Lin Li, Qingyang Hong, “ASV-Subtools: Open Source Toolkit for Automatic Speaker Verification”, ICASSP 2021.
https://ieeexplore.ieee.org/document/9414676